

파이프라인 효율성
GitLab v19.2Offering: GitLab.com, GitLab Self-Managed, GitLab Dedicated
CI/CD 파이프라인은 GitLab CI/CD의 기본 구성 요소입니다. 새로운 팀이나 프로젝트가 느리고 비효율적인 파이프라인으로 시작하여 시행착오를 통해 시간이 지남에 따라 구성을 개선하는 것은 흔한 일입니다. 먼저 GitLab CI/CD 기본 개념에 익숙해지고 빠른 시작 가이드를 이해합니다.
CI/CD 파이프라인은 GitLab CI/CD의 기본 구성 요소입니다. 파이프라인을 더 효율적으로 만들면 개발자 시간을 절약하는 데 도움이 됩니다:
- DevOps 프로세스 속도 향상
- 비용 절감
- 개발 피드백 루프 단축
새로운 팀이나 프로젝트가 느리고 비효율적인 파이프라인으로 시작하여 시행착오를 통해 시간이 지남에 따라 구성을 개선하는 것은 흔한 일입니다. 더 나은 프로세스는 즉시 효율성을 향상시키는 파이프라인 기능을 사용하여 더 빠른 소프트웨어 개발 라이프사이클을 더 일찍 얻는 것입니다.
먼저 GitLab CI/CD 기본 개념에 익숙해지고 빠른 시작 가이드를 이해합니다.
병목 지점 및 공통 실패 식별#
비효율적인 파이프라인을 확인하기 위한 가장 쉬운 지표는 잡, 스테이지의 런타임과 파이프라인 자체의 총 런타임입니다. 총 파이프라인 기간은 다음에 크게 영향을 받습니다:
GitLab Runner와 관련된 추가 사항:
- 러너의 가용성과 프로비저닝된 리소스.
- 빌드 의존성, 설치 시간, 스토리지 공간 요구 사항.
- 컨테이너 이미지 크기.
- 네트워크 지연 및 느린 연결.
불필요하게 실패하는 파이프라인도 개발 라이프사이클의 속도 저하를 유발합니다. 실패한 잡에서 문제 패턴을 찾아야 합니다:
- 임의로 실패하거나 신뢰할 수 없는 테스트 결과를 생성하는 불안정한 단위 테스트.
- 해당 동작과 관련된 테스트 커버리지 감소 및 코드 품질.
- 안전하게 무시할 수 있지만 파이프라인을 중단시키는 실패.
- 긴 파이프라인의 끝에서 실패하지만 더 이른 스테이지에 있었을 수도 있는 테스트로 인해 피드백이 지연됩니다.
파이프라인 분석#
파이프라인의 성능을 분석하여 효율성을 향상시킬 방법을 찾습니다. 분석은 CI/CD 인프라의 가능한 병목 지점을 식별하는 데 도움이 될 수 있습니다. 여기에는 다음 분석이 포함됩니다:
- 잡 워크로드.
- 실행 시간의 병목 지점.
- 전체 파이프라인 아키텍처.
파이프라인 워크플로우를 이해하고 문서화하며 가능한 작업과 변경 사항을 논의하는 것이 중요합니다. 파이프라인 리팩토링은 DevSecOps 라이프사이클에서 팀 간의 신중한 상호 작용이 필요할 수 있습니다.
파이프라인 분석은 비용 효율성 문제를 식별하는 데 도움이 될 수 있습니다. 예를 들어 유료 클라우드 서비스로 호스팅된 러너는 다음으로 프로비저닝될 수 있습니다:
- CI/CD 파이프라인에 필요한 것보다 더 많은 리소스로 돈을 낭비.
- 충분하지 않은 리소스로 런타임이 느리고 시간 낭비.
파이프라인 인사이트#
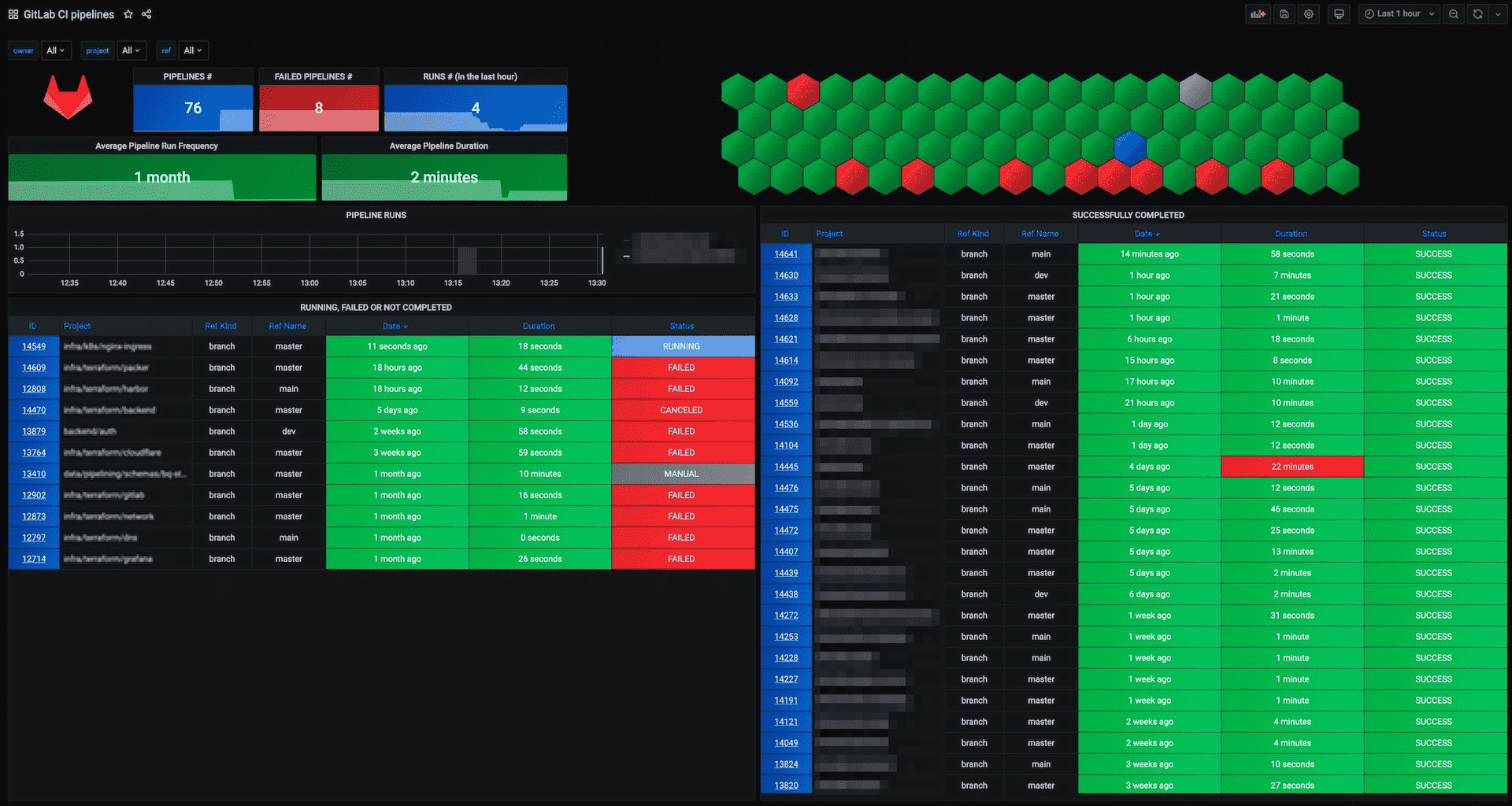
파이프라인 성공 및 기간 차트는 파이프라인 런타임 및 실패 잡 수에 대한 정보를 제공합니다.
단위 테스트, 통합 테스트, 엔드투엔드 테스트, 코드 품질 테스트 등은 CI/CD 파이프라인에서 문제를 자동으로 찾도록 합니다. 긴 런타임을 유발하는 많은 파이프라인 스테이지가 있을 수 있습니다.
동일한 스테이지에서 서로 다른 것을 테스트하는 잡을 병렬로 실행하여 전체 런타임을 줄임으로써 런타임을 향상시킬 수 있습니다. 단점은 병렬 잡을 지원하기 위해 동시에 실행되는 더 많은 러너가 필요하다는 것입니다.
needs 의존성 시각화#
전체 파이프라인 그래프에서 needs 의존성을 보면 파이프라인의 중요 경로를 분석하고 가능한 병목 지점을 이해하는 데 도움이 됩니다.
파이프라인 모니터링#
글로벌 파이프라인 상태는 잡 및 파이프라인 기간과 함께 모니터링할 주요 지표입니다. CI/CD 분석은 파이프라인 상태의 시각적 표현을 제공합니다.
인스턴스 관리자는 추가 성능 메트릭 및 자체 모니터링에 접근할 수 있습니다.
API에서 특정 파이프라인 상태 메트릭을 가져올 수 있습니다. 외부 모니터링 도구는 API를 폴링하여 파이프라인 상태를 확인하거나 장기적인 SLA 분석을 위한 메트릭을 수집할 수 있습니다.
예를 들어 Prometheus용 GitLab CI Pipelines Exporter는 API와 파이프라인 이벤트에서 메트릭을 가져옵니다. 프로젝트의 브랜치를 자동으로 확인하고 파이프라인 상태 및 기간을 가져올 수 있습니다. Grafana 대시보드와 결합하면 운영 팀을 위한 실행 가능한 보기를 구축하는 데 도움이 됩니다. 메트릭 그래프는 문제 해결을 더 쉽게 만드는 인시던트에 내장될 수도 있습니다. 또한 잡 및 환경에 대한 메트릭을 내보낼 수도 있습니다.
GitLab CI Pipelines Exporter를 사용하는 경우 예시 구성으로 시작해야 합니다.
또는 예를 들어 스크립트를 실행할 수 있는 check_gitlab과 같은 모니터링 도구를 사용할 수 있습니다.
러너 모니터링#
호스트 시스템이나 Kubernetes와 같은 클러스터에서 CI 러너를 모니터링할 수도 있습니다. 여기에는 다음 확인이 포함됩니다:
- 디스크 및 디스크 IO
- CPU 사용량
- 메모리
- 러너 프로세스 리소스
Prometheus Node Exporter는 Linux 호스트에서 러너를 모니터링할 수 있으며, kube-state-metrics는 Kubernetes 클러스터에서 실행됩니다.
클라우드 공급자와 함께 GitLab Runner 자동 스케일링을 테스트하고 비용을 줄이기 위해 오프라인 시간을 정의할 수도 있습니다.
대시보드 및 인시던트 관리#
기존 모니터링 도구와 대시보드를 사용하여 CI/CD 파이프라인 모니터링을 통합하거나 처음부터 구축합니다. 런타임 데이터가 팀에서 실행 가능하고 유용한지 확인하고 운영/SRE가 문제를 충분히 일찍 식별할 수 있도록 합니다. 인시던트 관리도 내장된 메트릭 차트와 문제를 분석하는 데 필요한 모든 유용한 세부 정보와 함께 도움이 될 수 있습니다.
스토리지 사용량#
비용과 효율성을 분석하는 데 도움이 되도록 다음의 스토리지 사용량을 검토합니다:
- 잡 아티팩트와 그것의
expire_in구성. 너무 오래 보관되면 스토리지 사용량이 증가하고 파이프라인이 느려질 수 있습니다. - 컨테이너 레지스트리 사용량.
- 패키지 레지스트리 사용량.
파이프라인 구성#
파이프라인을 빠르게 만들고 리소스 사용량을 줄이기 위해 파이프라인을 구성할 때 신중하게 선택합니다. 여기에는 파이프라인을 더 빠르고 효율적으로 실행하게 만드는 GitLab CI/CD의 내장 기능을 활용하는 것이 포함됩니다.
잡 실행 빈도 줄이기#
모든 상황에서 실행할 필요가 없는 잡을 찾아 파이프라인 구성을 사용하여 실행을 중지합니다:
interruptible키워드를 사용하여 더 새로운 파이프라인으로 대체될 때 이전 파이프라인을 중지합니다.rules를 사용하여 필요하지 않은 테스트를 건너뜁니다. 예를 들어 프런트엔드 코드만 변경될 때 백엔드 테스트를 건너뜁니다.- 필수적이지 않은 예약된 파이프라인을 덜 자주 실행합니다.
- 시스템 부하를 방지하기 위해 시간 전체에 걸쳐
cron스케줄을 균등하게 분산합니다.
빠른 실패#
CI/CD 파이프라인에서 오류가 초기에 감지되도록 합니다. 완료하는 데 매우 긴 시간이 걸리는 잡은 잡이 완료될 때까지 파이프라인이 실패 상태를 반환하지 못하도록 합니다.
빠른 실패가 가능한 잡이 더 일찍 실행되도록 파이프라인을 설계합니다. 예를 들어 초기 스테이지를 추가하고 구문, 스타일 린팅, Git 커밋 메시지 확인 및 유사한 잡을 거기에 이동합니다.
더 빠른 잡에서 빠른 피드백이 오기 전에 긴 잡을 일찍 실행하는 것이 중요한지 결정합니다. 초기 실패로 나머지 파이프라인이 실행되어서는 안 된다는 것이 분명해져 파이프라인 리소스를 절약할 수 있습니다.
needs 키워드#
기본 구성에서 잡은 항상 이전 스테이지의 다른 모든 잡이 완료될 때까지 기다렸다가 실행됩니다. 이것은 가장 간단한 구성이지만 대부분의 경우 가장 느린 방법입니다. needs 키워드가 있는 파이프라인과 부모/자식 파이프라인은 더 유연하고 더 효율적일 수 있지만 파이프라인을 이해하고 분석하기 어렵게 만들 수도 있습니다.
캐싱#
또 다른 최적화 방법은 의존성을 캐시하는 것입니다. NodeJS /node_modules와 같이 의존성이 거의 변경되지 않으면 캐싱으로 파이프라인 실행이 훨씬 빨라질 수 있습니다.
cache:when을 사용하여 잡이 실패할 때도 다운로드된 의존성을 캐시할 수 있습니다.
Docker 이미지#
Docker 이미지를 다운로드하고 초기화하는 것은 잡의 전체 런타임의 큰 부분을 차지할 수 있습니다.
Docker 이미지가 잡 실행을 느리게 한다면 기본 이미지 크기와 레지스트리에 대한 네트워크 연결을 분석합니다. GitLab이 클라우드에서 실행 중이면 공급업체가 제공하는 클라우드 컨테이너 레지스트리를 찾습니다. 그 외에도 다른 레지스트리보다 GitLab 인스턴스에서 더 빠르게 액세스할 수 있는 GitLab 컨테이너 레지스트리를 활용할 수 있습니다.
Docker 이미지 최적화#
대용량 Docker 이미지는 많은 공간을 차지하고 느린 연결 속도에서 다운로드하는 데 오랜 시간이 걸리기 때문에 최적화된 Docker 이미지를 구축합니다. 가능하면 모든 잡에 하나의 큰 이미지를 사용하지 마세요. 특정 작업을 위한 각각 더 빠르게 다운로드하고 실행되는 여러 개의 작은 이미지를 사용합니다.
소프트웨어가 사전 설치된 사용자 정의 Docker 이미지를 사용하는 것을 시도합니다. 일반적인 이미지를 사용하고 매번 소프트웨어를 설치하는 것보다 미리 구성된 더 큰 이미지를 다운로드하는 것이 훨씬 빠릅니다. Docker Dockerfile 작성을 위한 모범 사례 문서는 효율적인 Docker 이미지를 빌드하는 방법에 대한 자세한 내용을 제공합니다.
Docker 이미지 크기를 줄이는 방법:
debian-slim과 같은 작은 기본 이미지를 사용합니다.- 꼭 필요하지 않으면 vim 또는 curl과 같은 편의 도구를 설치하지 마세요.
- 전용 개발 이미지를 만듭니다.
- 공간을 절약하기 위해 패키지로 설치된 man 페이지 및 문서를 비활성화합니다.
RUN레이어를 줄이고 소프트웨어 설치 단계를 결합합니다.- 멀티 스테이지 빌드를 사용하여 빌더 패턴을 사용하는 여러 Dockerfile을 하나의 Dockerfile로 병합하면 이미지 크기를 줄일 수 있습니다.
apt를 사용하는 경우 불필요한 패키지를 피하기 위해--no-install-recommends를 추가합니다.- 마지막에 더 이상 필요하지 않은 캐시 및 파일을 정리합니다. 예를 들어 Debian 및 Ubuntu의 경우
rm -rf /var/lib/apt/lists/*, RHEL 및 CentOS의 경우yum clean all. - dive 또는 DockerSlim과 같은 도구를 사용하여 이미지를 분석하고 축소합니다.
Docker 이미지 관리를 간소화하기 위해 Docker 이미지 관리를 위한 전용 그룹을 만들고 CI/CD 파이프라인으로 이미지를 테스트, 빌드, 게시할 수 있습니다.
테스트, 문서화, 학습#
파이프라인 개선은 반복적인 프로세스입니다. 작은 변경을 하고 효과를 모니터링한 다음 다시 반복합니다. 많은 작은 개선이 파이프라인 효율성의 큰 증가로 이어질 수 있습니다.
파이프라인 설계 및 아키텍처를 문서화하는 것이 도움이 될 수 있습니다. GitLab 리포지터리에서 직접 Markdown의 Mermaid 차트를 사용하여 이를 수행할 수 있습니다.
이슈에 수행된 연구 및 발견된 해결책을 포함하여 CI/CD 파이프라인 문제 및 인시던트를 문서화합니다. 이는 새 팀 구성원 온보딩에 도움이 되며 CI 파이프라인 효율성에 대한 반복적인 문제를 식별하는 데도 도움이 됩니다.
관련 항목#
- CI 모니터링 웨비나 슬라이드
- GitLab.com 모니터링 핸드북
- 운영 가시성을 위한 대시보드 구축