

GitLab Runner 매니저 파드 성능 최적화
GitLab v19.2Offering: GitLab.com, GitLab Self-Managed, GitLab Dedicated
Kubernetes 환경에서 GitLab Runner 매니저 파드 성능을 모니터링하고 최적화하려면 GitLab이 권장하는 다음 모범 사례를 따르세요. 이 권장 사항을 구현하기 전에 다음을 확인하세요: GitLab Runner 매니저 파드는 Kubernetes에서 모든 CI/CD 작업 실행을 조율합니다.
Kubernetes 환경에서 GitLab Runner 매니저 파드 성능을 모니터링하고 최적화하려면 GitLab이 권장하는 다음 모범 사례를 따르세요. 이를 적용하여 성능 병목 현상을 파악하고 최적의 CI/CD 파이프라인 실행을 위한 솔루션을 구현하세요.
사전 요구 사항#
이 권장 사항을 구현하기 전에 다음을 확인하세요:
- Kubernetes 실행기를 사용하여 Kubernetes에 GitLab Runner 배포
- Kubernetes 클러스터에 대한 관리자 접근 권한 보유
- GitLab Runner를 위한 Prometheus 모니터링 구성
- Kubernetes 리소스 관리에 대한 기본 이해
GitLab Runner 매니저 파드의 역할#
GitLab Runner 매니저 파드는 Kubernetes에서 모든 CI/CD 작업 실행을 조율합니다. 매니저 파드의 성능은 파이프라인 효율에 직접적인 영향을 미칩니다.
매니저 파드가 처리하는 작업:
- 로그 처리: 워커 파드에서 작업 로그를 수집하여 GitLab으로 전달
- 캐시 관리: 로컬 및 클라우드 기반 캐싱 작업 조율
- Kubernetes API 요청: 워커 파드 생성, 모니터링, 삭제
- GitLab API 통신: 작업 폴링 및 상태 업데이트 보고
- 파드 라이프사이클 관리: 워커 파드 프로비저닝 및 정리 관리
소스 코드 보기
%%{init: { "fontFamily": "GitLab Sans" }}%%
flowchart LR
accTitle: GitLab Runner manager pod architecture
accDescr: The manager pod polls GitLab for jobs, creates job pods through the Kubernetes API, manages the S3 cache, and forwards logs from job pods to GitLab.
subgraph "External Services"
GL[GitLab Instance]
S3[S3 Cache Storage]
end
subgraph "Manager Pod"
MP[Manager Process]
LB[Log Buffer]
CM[Cache Manager]
end
subgraph "Kubernetes API"
K8S[API Server]
end
subgraph "Job Pods"
JP1[Job Pod 1]
JP2[Job Pod 2]
JP3[Job Pod N]
end
GL <-->|Poll Jobs<br/>Update Status| MP
MP <-->|Create/Delete<br/>Monitor Pods| K8S
MP <-->|Cache Operations| S3
JP1 -->|Stream Logs| LB
JP2 -->|Stream Logs| LB
JP3 -->|Stream Logs| LB
LB -->|Forward Logs| GL
CM <-->|Manage Cache| S3</code></pre></details></div>
각 역할은 성능에 서로 다른 영향을 미칩니다:
- CPU 집약적: Kubernetes API 작업, 로그 처리
- 메모리 집약적: 로그 버퍼링, 작업 큐 관리
- 네트워크 집약적: GitLab API 통신, 로그 스트리밍
Kubernetes에 GitLab Runner 배포#
GitLab Runner Operator를 통해 GitLab Runner를 설치하세요.
Operator는 새로운 기능과 개선 사항을 지속적으로 받고 있습니다.
GitLab Runner 팀은
Experimental GRIT framework를 통해 Operator를 설치합니다.
Kubernetes에 GitLab Runner를 설치하는 가장 쉬운 방법은
최신 릴리스의 operator.k8s.yaml 매니페스트를 적용한 다음
Operator 설치 문서의 안내를 따르는 것입니다.
모니터링 구성#
Kubernetes에서 GitLab Runner를 관리할 때 관찰 가능성이 매우 중요합니다.
파드는 임시적이며 메트릭이 주요 운영 가시성을 제공하기 때문입니다.
모니터링을 위해 kube-prometheus-stack을 설치하세요.
Operator에 대한 모니터링 구성 방법은 GitLab Runner Operator 모니터링을 참고하세요.
성능 모니터링#
효과적인 모니터링은 매니저 파드의 최적 성능 유지에 필수적입니다.
Mermaid 다이어그램 (18줄)소스 코드 보기
%%{init: { "fontFamily": "GitLab Sans" }}%%
flowchart TD
accTitle: Metrics collection and monitoring flow
accDescr: The manager pod exposes metrics, Prometheus scrapes the metrics using PodMonitor configuration, Grafana visualizes the data, and Alertmanager notifies operators.
subgraph "Metrics Collection Flow"
MP[Manager Pod<br/>:9252/metrics]
PM[PodMonitor]
P[Prometheus]
G[Grafana]
A[Alertmanager]
MP -->|Expose Metrics| PM
PM -->|Scrape| P
P -->|Query| G
P -->|Alerts| A
A -->|Notify| O[Operators]
end</code></pre></details></div>
주요 성능 메트릭#
다음 필수 메트릭을 모니터링하세요:
메트릭
설명
성능 지표
gitlab_runner_jobs현재 실행 중인 작업
작업 큐 포화도
gitlab_runner_limit구성된 작업 동시성 한도
용량 활용률
gitlab_runner_request_concurrency_exceeded_total동시성 한도를 초과한 요청
API 스로틀링
gitlab_runner_errors_total감지된 총 오류 수
시스템 안정성
container_cpu_usage_seconds_total컨테이너 CPU 사용량
리소스 소비
container_memory_working_set_bytes컨테이너 메모리 사용량
메모리 압박
Prometheus 쿼리#
다음 쿼리로 매니저 파드 성능을 추적하세요:
# Manager pod memory usage in MB
container_memory_working_set_bytes{pod=~"gitlab-runner.*"} / 1024 / 1024
# Manager pod CPU utilization in Millicores
rate(container_cpu_usage_seconds_total{pod=~"gitlab-runner.*"}[5m]) * 1000
# Job queue saturation
gitlab_runner_jobs / gitlab_runner_limit
# Jobs per runner
gitlab_runner_jobs
# API request rate
sum(rate(apiserver_request_total[5m]))
대시보드 예시#
다음 대시보드는 앞서 설명한 Prometheus 쿼리를 사용하여 모든 파드에 걸친 매니저 파드 활용도를 보여줍니다:
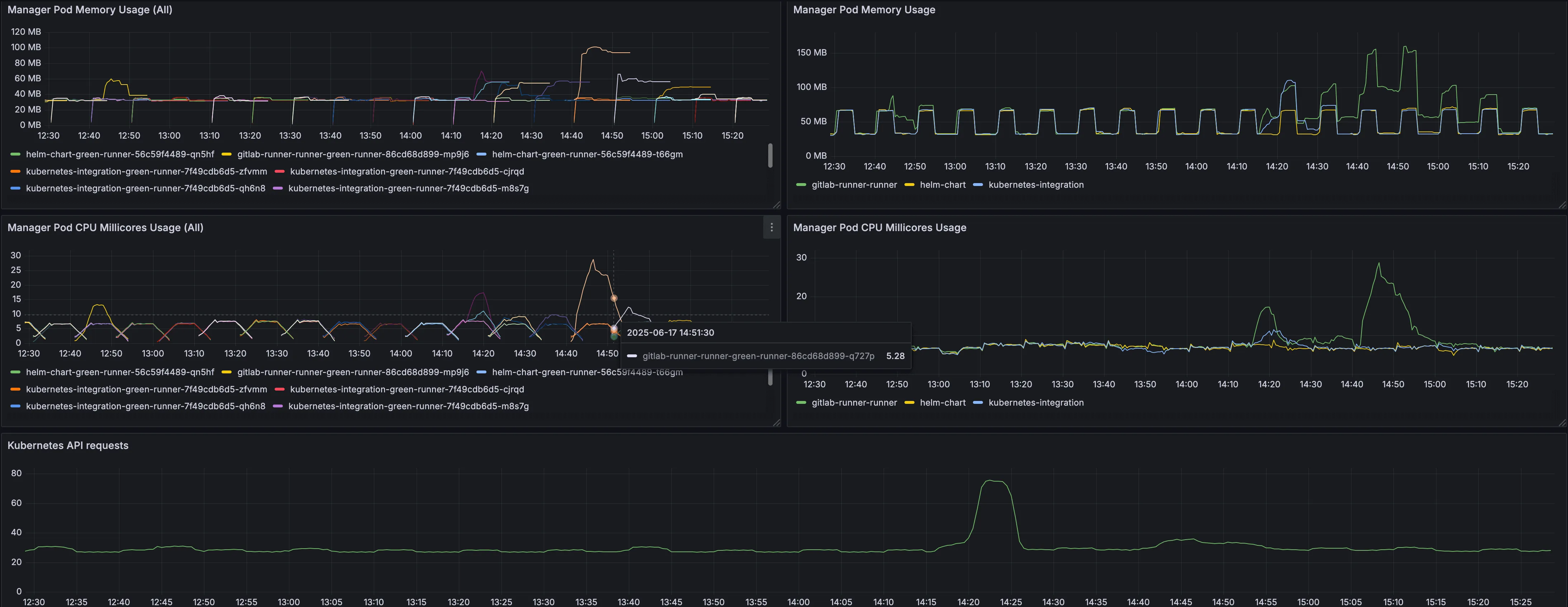
이 대시보드를 통해 다음 사항을 시각화할 수 있습니다:
- 매니저 파드 전반의 메모리 사용량 추이
- 작업 실행 중 CPU 활용 패턴
- 작업 큐 포화도 수준
- 개별 파드의 리소스 소비량
과부하된 매니저 파드 식별#
파이프라인에 영향을 미치기 전에 성능 저하를 미리 파악하세요.
리소스 활용 지표#
기본적으로 GitLab Runner Operator는 매니저 파드에 CPU 또는 메모리 제한을 적용하지 않습니다.
리소스 제한을 설정하려면:
kubectl patch deployment gitlab-runner -p '{"spec":{"template":{"spec":{"containers":[{"name":"gitlab-runner","resources":{"requests":{"cpu":"500m","memory":"256Mi"},"limits":{"cpu":"1000m","memory":"512Mi"}}}]}}}}'
Note
Operator 구성에서 배포 패칭을 허용하는 기능은 개발 중입니다.
자세한 내용은 merge request 197을 참고하세요.
높은 CPU 사용 패턴:
- 일반 작업 중 CPU가 지속적으로 70% 이상
- 작업 생성 중 CPU가 90%를 초과하는 스파이크
- 상응하는 작업 활동 없이 지속적으로 높은 CPU
메모리 소비 추이:
- 메모리 사용량이 할당 제한의 80% 이상
- 워크로드 증가 없이 지속적인 메모리 증가
- 매니저 파드 로그의 OOM(Out-of-Memory) 이벤트
성능 저하 징후#
다음 운영 증상에 주의하세요:
- 작업이 평소보다 오래 대기 상태로 유지
- 파드 생성 시간이 30초를 초과
- GitLab 작업 인터페이스에서 지연된 로그 출력
- 로그의
etcdserver: request timed out 오류
진단 명령#
# Current resource usage
kubectl top pods --containers
> POD NAME CPU(cores) MEMORY(bytes)
> gitlab-runner-runner-86cd68d899-m6qqm runner 7m 32Mi
# Check for performance errors
kubectl logs gitlab-runner-runner-86cd68d899-m6qqm --since=2h | grep -E "(error|timeout|failed)"
리소스 구성#
최적의 성능을 위해 적절한 리소스 구성이 필수적입니다.
성능 테스트 방법론#
GitLab Runner 매니저 파드 성능은 로그 출력을 최대화하는 작업을 사용하여 테스트됩니다:
성능 테스트 작업 정의
performance_test:
stage: build
timeout: 30m
tags:
- kubernetes_runner
image: alpine:latest
parallel: 100
variables:
FILE_SIZE_MB: 4
CHUNK_SIZE_BYTES: 1024
FILE_NAME: "test_file_${CI_JOB_ID}_${FILE_SIZE_MB}MB.dat"
KUBERNETES_CPU_REQUEST: "200m"
KUBERNETES_CPU_LIMIT: "200m"
KUBERNETES_MEMORY_REQUEST: "200Mi"
KUBERNETES_MEMORY_LIMIT: "200Mi"
script:
- echo "Starting performance test job ${CI_PARALLEL_ID}/${CI_PARALLEL_TOTAL} with ${FILE_SIZE_MB}MB file size, ${CHUNK_SIZE_BYTES} bytes chunk size"
- dd if=/dev/urandom of="${FILE_NAME}" bs=1M count=${FILE_SIZE_MB}
- echo "File generated successfully. Size:"
- ls -lh "${FILE_NAME}"
- echo "Reading file in ${CHUNK_SIZE_BYTES} byte chunks"
- |
TOTAL_SIZE=$(stat -c%s "${FILE_NAME}")
BLOCKS=$((TOTAL_SIZE / CHUNK_SIZE_BYTES))
echo "Processing $BLOCKS blocks of $CHUNK_SIZE_BYTES bytes each"
for i in $(seq 0 99 $BLOCKS); do
echo "Processing blocks $i to $((i+99))"
dd if="${FILE_NAME}" bs=${CHUNK_SIZE_BYTES} skip=$i count=100 2>/dev/null | xxd -l $((CHUNK_SIZE_BYTES * 100)) -c 16
sleep 0.5
done
이 테스트는 작업당 4MB의 로그 출력을 생성하며, 기본
output_limit에
도달하여 매니저 파드의 로그 처리 능력을 스트레스 테스트합니다.
테스트 결과:
병렬 작업 수
최대 CPU 사용량
최대 메모리 사용량
50
308m
261 MB
100
657m
369 MB
Mermaid 다이어그램 (9줄)소스 코드 보기
%%{init: { "fontFamily": "GitLab Sans" }}%%
xychart-beta
accTitle: Manager pod resource usage compared to concurrent jobs
accDescr: Chart showing CPU usage (10-610 millicores) and memory usage (50-300 MB) that scale with concurrent jobs (0-100).
x-axis [0, 25, 50, 75, 100]
y-axis "Resource Usage" 0 --> 700
line "CPU (millicores)" [10, 160, 310, 460, 610]
line "Memory (MB)" [50, 112, 175, 237, 300]</code></pre></details></div>
주요 발견 사항:
- CPU 사용량은 동시 작업 수에 따라 거의 선형적으로 증가
- 메모리 사용량은 작업 수에 따라 증가하지만 선형적이지 않음
- 모든 작업이 큐 없이 동시에 실행됨
CPU 요구 사항#
GitLab 성능 테스트를 기반으로 매니저 파드 CPU 요구 사항을 계산하세요:
매니저 파드 CPU = 기본 CPU + (동시 작업 수 × 작업당 CPU 계수)
여기서:
- 기본 CPU: 10m (기준 오버헤드)
- 작업당 CPU 계수: 동시 작업당 약 6m (테스트 기반)
테스트 결과에 기반한 예시:
50개 동시 작업의 경우:
resources:
requests:
cpu: "310m" # 10m + (50 × 6m) = 310m
limits:
cpu: "465m" # 버스트 트래픽을 위한 50% 여유분
100개 동시 작업의 경우:
resources:
requests:
cpu: "610m" # 10m + (100 × 6m) = 610m
limits:
cpu: "915m" # 50% 여유분
메모리 요구 사항#
GitLab 테스트를 기반으로 메모리 요구 사항을 계산하세요:
매니저 파드 메모리 = 기본 메모리 + (동시 작업 수 × 작업당 메모리)
여기서:
- 기본 메모리: 50MB (기준 오버헤드)
- 작업당 메모리: 동시 작업당 약 2.5MB (4MB 로그 출력 기준)
테스트 결과에 기반한 예시:
50개 동시 작업의 경우:
resources:
requests:
memory: "175Mi" # 50 + (50 × 2.5) = 175 MB
limits:
memory: "350Mi" # 100% 여유분
100개 동시 작업의 경우:
resources:
requests:
memory: "300Mi" # 50 + (100 × 2.5) = 300 MB
limits:
memory: "600Mi" # 100% 여유분
Note
메모리 사용량은 로그 볼륨에 따라 크게 달라집니다. 4MB 이상의 로그를 생성하는 작업은
비례하여 더 많은 메모리를 필요로 합니다.
구성 예시#
소규모 (동시 작업 1-20개):
resources:
limits:
cpu: 300m
memory: 256Mi
requests:
cpu: 150m
memory: 128Mi
runners:
config: |
concurrent = 20
[[runners]]
limit = 20
request_concurrency = 5
대규모 (동시 작업 75개 이상):
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 600m
memory: 600Mi
runners:
config: |
concurrent = 150
[[runners]]
limit = 150
request_concurrency = 20
수평적 파드 오토스케일러#
자동 스케일링을 구성하세요:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: gitlab-runner-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: gitlab-runner
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
성능 문제 해결#
일반적인 매니저 파드 성능 문제를 다음 솔루션으로 해결하세요.
API 속도 제한#
문제: 매니저 파드가 Kubernetes API 속도 제한을 초과합니다.
해결 방법: API 폴링을 최적화하세요:
[[runners]]
[runners.kubernetes]
poll_interval = "5s" # Increase from default 3s
poll_timeout = "180s"
성능 최적화#
어려운 시나리오를 위해 다음 성능 최적화 전략을 적용하세요.
캐시 최적화#
매니저 파드 부하를 줄이기 위해 분산 캐싱을 구성하세요. 이 조치는 캐시된 파일을 공유하여
작업 파드에 필요한 연산을 줄입니다:
[runners.cache]
Type = "s3"
Shared = true
[runners.cache.s3]
ServerAddress = "cache.example.com"
BucketName = "gitlab-runner-cache"
PreSignedURLDisabled = false
노드 분리#
전용 노드를 사용하여 매니저 파드를 작업 파드와 분리하면 안정적인 성능을 보장하고
리소스 경합을 방지할 수 있습니다. 이 격리를 통해 작업 파드가 중요한 매니저 파드 작업을
방해하는 것을 방지합니다.
Mermaid 다이어그램 (34줄)소스 코드 보기
%%{init: { "fontFamily": "GitLab Sans" }}%%
graph TB
accTitle: Kubernetes node segregation architecture
accDescr: Node segregation with manager pods on dedicated manager nodes and job pods on worker nodes, separated by taints.
subgraph "Kubernetes Cluster"
subgraph "Manager Nodes"
MN1[Manager Node 1<br/>Taint: runner.gitlab.com/manager]
MN2[Manager Node 2<br/>Taint: runner.gitlab.com/manager]
MP1[Manager Pod 1]
MP2[Manager Pod 2]
MN1 --> MP1
MN2 --> MP2
end
subgraph "Worker Nodes"
WN1[Worker Node 1<br/>Taint: runner.gitlab.com/job]
WN2[Worker Node 2<br/>Taint: runner.gitlab.com/job]
WN3[Worker Node 3<br/>Taint: runner.gitlab.com/job]
JP1[Job Pod 1]
JP2[Job Pod 2]
JP3[Job Pod 3]
JP4[Job Pod 4]
WN1 --> JP1
WN1 --> JP2
WN2 --> JP3
WN3 --> JP4
end
end
MP1 -.->|Creates & Manages| JP1
MP1 -.->|Creates & Manages| JP2
MP2 -.->|Creates & Manages| JP3
MP2 -.->|Creates & Manages| JP4</code></pre></details></div>
노드 테인트 구성#
매니저 노드의 경우:
# Taint nodes dedicated to Manager Pods
kubectl taint nodes <manager-node-name> runner.gitlab.com/manager=:NoExecute
# Label nodes for easier selection
kubectl label nodes <manager-node-name> runner.gitlab.com/workload-type=manager
워커 노드의 경우:
# Taint nodes dedicated to job pods
kubectl taint nodes <worker-node-name> runner.gitlab.com/job=:NoExecute
# Label nodes for job scheduling
kubectl label nodes <worker-node-name> runner.gitlab.com/workload-type=job
매니저 파드 스케줄링 구성#
GitLab Runner Operator 구성을 업데이트하여 매니저 파드가 전용 노드에만 스케줄링되도록 하세요:
apiVersion: apps.gitlab.com/v1beta2
kind: Runner
metadata:
name: gitlab-runner
spec:
gitlabUrl: https://gitlab.example.com
token: gitlab-runner-secret
buildImage: alpine
podSpec:
name: "manager-node-affinity"
patch: |
{
"spec": {
"nodeSelector": {
"runner.gitlab.com/workload-type": "manager"
},
"tolerations": [
{
"key": "runner.gitlab.com/manager",
"operator": "Exists",
"effect": "NoExecute"
}
]
}
}
patchType: "strategic"
작업 파드 스케줄링 구성#
config.toml을 업데이트하여 작업 파드가 워커 노드에서만 실행되도록 하세요.
[runners.kubernetes.node_selector]
"runner.gitlab.com/workload-type" = "job"
[runners.kubernetes.node_tolerations]
"runner.gitlab.com/job=" = "NoExecute"
노드 분리의 이점:
- 작업 방해 없이 매니저 파드를 위한 전용 리소스 확보
- 리소스 경합 없는 예측 가능한 성능
- 전용 노드 사용 시 리소스 제한 없이 실행 가능
- 노드 기반 스케일링으로 용량 계획 단순화
긴급 절차#
정상적인 재시작:
# Scale down to stop accepting new jobs
kubectl scale deployment gitlab-runner --replicas=0
# Wait for active jobs to complete (max 10 minutes)
timeout 600 bash -c 'while kubectl get pods -l job-type=user-job | grep Running; do sleep 10; done'
# Scale back up
kubectl scale deployment gitlab-runner --replicas=1
용량 계획#
이 계산은 작업당 4MB 로그 출력 테스트를 기반으로 합니다.
실제 리소스 요구 사항은 다음에 따라 달라질 수 있습니다:
- 작업당 로그 볼륨
- 작업 실행 패턴
- 캐시 사용량
- GitLab과의 네트워크 지연
다음 Python 함수를 사용하여 최적의 리소스를 계산하세요:
def calculate_manager_resources(concurrent_jobs, avg_log_mb_per_job=4):
"""Calculate Manager Pod resources based on performance testing."""
# CPU: ~6m per concurrent job + 10m base
base_cpu = 0.01 # 10m
cpu_per_job = 0.006 # 6m per job
total_cpu = base_cpu + (concurrent_jobs * cpu_per_job)
# Memory: ~2.5MB per job + 50MB base (for 4MB log output)
base_memory = 50
memory_per_job = 2.5 * (avg_log_mb_per_job / 4) # Scale with log size
total_memory = base_memory + (concurrent_jobs * memory_per_job)
return {
'cpu_request': f"{int(total_cpu * 1000)}m",
'cpu_limit': f"{int(total_cpu * 1.5 * 1000)}m", # 50% headroom
'memory_request': f"{int(total_memory)}Mi",
'memory_limit': f"{int(total_memory * 2.0)}Mi" # 100% headroom
}
성능 임계값#
사전 예방적 개입을 위한 임계값을 설정하세요:
메트릭
경고
위험
필요한 조치
CPU 사용량
70% 지속
85% 지속
스케일 또는 최적화
메모리 사용량
제한의 80%
제한의 90%
제한 증가
API 오류율
요청의 2%
요청의 5%
병목 현상 조사
작업 큐 대기 시간
30초
2분
용량 검토
관련 항목#
- GitLab Runner 플릿 구성 및 모범 사례 - 작업 파드 성능 최적화
- GitLab Runner 실행기 - 실행 환경 성능 특성
- GitLab Runner 모니터링 - 일반 모니터링 설정
- 러너 플릿 계획 및 운영 - 전략적 플릿 배포
요약#
GitLab Runner 매니저 파드 성능 최적화는 체계적인 모니터링, 적절한 리소스 할당,
그리고 사전 예방적 문제 해결이 필요합니다.
주요 전략:
- 사전 예방적 모니터링: Prometheus 메트릭과 Grafana 대시보드 활용
- 리소스 계획: 동시 작업 용량과 로그 볼륨을 기반으로 계획
- 멀티 매니저 아키텍처: 내결함성과 부하 분산을 위한 구성
- 긴급 절차: 신속한 문제 해결을 위한 준비
이 전략을 구현하여 최적의 리소스 활용을 유지하면서 안정적인 CI/CD 파이프라인 실행을 보장하세요.