

Teleport Kubernetes 헬스 체크
Teleport v18.9Teleport Kubernetes 헬스 체크를 사용하면 Teleport Kubernetes Service 인스턴스가 등록된 Kubernetes 클러스터의 연결성과 권한을 주기적으로 확인합니다. Kubernetes 클러스터 헬스 체크는 Teleport 버전 [ kubernetes.health_check_min_version ] 이상에서 사용할 수 있습니다.
Teleport Kubernetes 헬스 체크를 사용하면 Teleport Kubernetes Service 인스턴스가 등록된 Kubernetes 클러스터의 연결성과 권한을 주기적으로 확인합니다. 이 문서에서는 Kubernetes 헬스 체크의 작동 방식과 클러스터에 대해 헬스 체크를 구성하는 방법을 설명합니다.
Kubernetes 클러스터 헬스 체크는 Teleport 버전 [ kubernetes.health_check_min_version ] 이상에서 사용할 수 있습니다.
Teleport Kubernetes 헬스 체크는 다음을 제공합니다:
- 관찰 가능성: 사용자보다 먼저 네트워크 및 권한 문제를 발견합니다. 비정상 Kubernetes 클러스터는 Teleport UI, 명령줄 도구 또는 Prometheus 메트릭에서 확인할 수 있습니다.
- 고가용성: 고가용성 구성에서 정상 Kubernetes 클러스터로 연결을 자동으로 라우팅하고 분산합니다.
Kubernetes 헬스 체크 작동 방식#
Teleport Kubernetes Service는 Kubernetes 클러스터가 정상 작동 중이며 Teleport와 함께 사용 가능한지 확인하기 위해 Kubernetes 권한과 헬스 엔드포인트를 점검합니다.
4가지 Kubernetes RBAC 권한이 Kubernetes SelfSubjectAccessReview API를 통해 정기적으로 확인됩니다. 이 권한들은 Teleport가 Kubernetes 클러스터와 함께 작동하기 위한 최소 요구사항의 일부입니다. 확인되는 권한은 다음과 같습니다:
- 사용자 임퍼소네이션
- 그룹 임퍼소네이션
- 서비스 계정 임퍼소네이션
- 파드 조회
권한을 확인할 수 없는 경우, 연결 오류와 Kubernetes 컴포넌트 오류를 구분하기 위해 Kubernetes /readyz 엔드포인트가 호출됩니다.
헬스 상태#
Kubernetes 클러스터는 healthy, unhealthy, 또는 unknown 상태 중 하나입니다.
healthy는 Kubernetes 클러스터의 헬스가 확인되었고 정상임을 나타냅니다unhealthy는 Kubernetes 클러스터의 헬스가 확인되었으나 어떤 이유로 사용할 수 없음을 나타냅니다unknown은 Kubernetes 클러스터가 헬스 체크에서 제외되었거나, 첫 번째 헬스 체크가 초기화 중임을 나타냅니다
unknown Kubernetes 클러스터는 비정상일 수 있습니다.
unknown Kubernetes 클러스터는 다음과 같은 이유로 헬스 체크가 수행되지 않습니다:
[ kubernetes.health_check_min_version ]이전 버전의 Teleport Kubernetes Service 인스턴스를 실행 중인 경우health_check_config를 명시적으로 비활성화한 경우- Kubernetes 클러스터를 제외하도록
health_check_config레이블을 명시적으로 구성한 경우
헬스 확인#
Kubernetes 클러스터 헬스는 Teleport 웹 UI, 데스크톱 Connect UI, tctl CLI 도구, 또는 Prometheus 메트릭을 통해 확인할 수 있습니다.
Teleport 웹 UI 및 Teleport Connect#
Teleport 웹 및 Connect UI는 비정상 Kubernetes 클러스터를 강조 표시합니다.
강조 표시된 Kubernetes 클러스터를 클릭하면 비정상 Kubernetes 클러스터의 세부 정보가 표시됩니다.
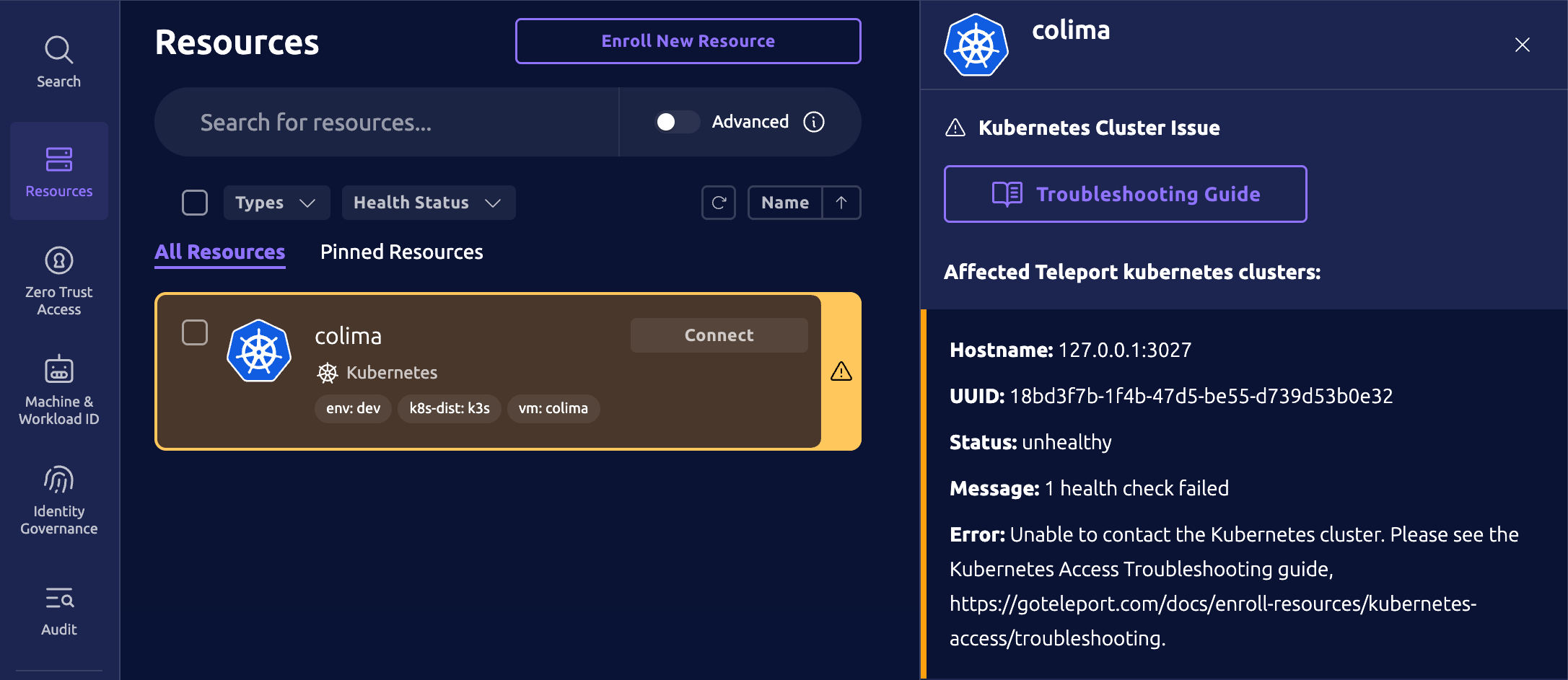
헬스 변경 사항이 보고되기까지 약 5m이 걸릴 수 있습니다.
원형 화살표 새로고침 아이콘을 클릭하면 최신 헬스 상태를 확인할 수 있습니다.
Teleport tctl CLI#
Teleport tctl CLI 도구는 비정상 Kubernetes 클러스터를 검색하고 표시합니다.
tctl kube ls --query 'health.status == "unhealthy"'
특정 Kubernetes 서비스의 Kubernetes 클러스터 헬스 개요를 확인하려면 tctl get kube_server/<your-kube-server-name>를 실행하세요.
kind: kube_server
...
status:
target_health:
address: 192.168.106.2:58458
message: 1 health check passed
protocol: http
status: healthy
transition_reason: threshold_reached
transition_timestamp: "2025-10-13T19:26:58.842855Z"
version: v3
Teleport Prometheus 메트릭#
헬스 체크 메트릭은 Kubernetes 클러스터 헬스에 대한 상위 수준의 뷰를 제공합니다. healthy, unhealthy, 또는 unknown 상태에 있는 Kubernetes 클러스터의 총 수는 게이지 메트릭 teleport_resources_health_status_healthy, teleport_resources_health_status_unhealthy, teleport_resources_health_status_unknown으로 모니터링됩니다.
teleport_resources_health_status_healthy{type="kubernetes"}는 정상 Kubernetes 클러스터의 총 수입니다teleport_resources_health_status_unhealthy{type="kubernetes"}는 비정상 Kubernetes 클러스터의 총 수입니다teleport_resources_health_status_unknown{type="kubernetes"}는 unknown 상태의 Kubernetes 클러스터 총 수입니다
PromQL 표현식을 사용하여 Kubernetes 클러스터의 총 수를 확인할 수 있습니다.
teleport_resources_health_status_healthy{type="kubernetes"} +
teleport_resources_health_status_unhealthy{type="kubernetes"} +
teleport_resources_health_status_unknown{type="kubernetes"}
PromQL 표현식을 사용하여 비정상 Kubernetes 클러스터의 존재 여부를 감지할 수 있습니다.
teleport_resources_health_status_unhealthy{type="kubernetes"} > 0
Prometheus 메트릭은 어떤 클러스터가 비정상인지 구분하지 않습니다.
비정상 클러스터를 확인하려면 Teleport 웹 UI, Teleport Connect, 또는 다음 tctl 명령을 사용하세요:
$ tctl kube ls --query 'health.status == "unhealthy"'
헬스 체크 메트릭은 Teleport 진단 엔드포인트 http://<diagnostic-address>/metrics에서도 확인할 수 있습니다.
# HELP teleport_resources_health_status_healthy Number of healthy resources
# TYPE teleport_resources_health_status_healthy gauge
teleport_resources_health_status_healthy{type="kubernetes"} 99972
# HELP teleport_resources_health_status_unhealthy Number of unhealthy resources
# TYPE teleport_resources_health_status_unhealthy gauge
teleport_resources_health_status_unhealthy{type="kubernetes"} 3
# HELP teleport_resources_health_status_unknown Number of resources in an unknown health state
# TYPE teleport_resources_health_status_unknown gauge
teleport_resources_health_status_unknown{type="kubernetes"} 25
진단 엔드포인트 메트릭은 기본적으로 비활성화되어 있습니다. 진단 메트릭을 활성화하는 방법은 Teleport 배포 모니터링을 참조하세요.
헬스 체크 구성#
Teleport tctl CLI 도구를 사용하면 health_check_config 리소스를 읽고, 추가하고, 편집하고, 삭제할 수 있습니다.
health_check_config 리소스는 헬스 체크를 구성하고 Kubernetes 클러스터에 선택적으로 적용하는 방법을 제공합니다.
예시 health_check_config.
kind: health_check_config
version: v1
metadata:
name: example
description: Example healthcheck configuration
spec:
# interval은 각 헬스 체크 사이의 시간입니다. 기본값 30s.
interval: 30s
# timeout은 헬스 체크 연결 설정 타임아웃입니다. 기본값 5s.
timeout: 5s
# healthy_threshold는 대상의 헬스 상태가 "healthy"가 되기 위해
# 연속으로 통과해야 하는 헬스 체크 횟수입니다. 기본값 2.
healthy_threshold: 2
# unhealthy_threshold는 대상의 헬스 상태가 "unhealthy"가 되기 위해
# 연속으로 실패해야 하는 헬스 체크 횟수입니다. 기본값 1.
unhealthy_threshold: 1
# match는 이 설정을 적용할 Kubernetes 클러스터를 선택하는 데 사용됩니다.
# Kubernetes 클러스터는 레이블 셀렉터로 매칭되며 최소 하나의 레이블 셀렉터가
# 설정되어야 합니다.
# 동일한 Kubernetes 클러스터에 여러 `health_check_config` 리소스가 매칭될 경우,
# 매칭된 헬스 체크 구성은 이름 순으로 정렬되고 첫 번째 구성만 적용됩니다.
match:
# 이 구성의 모든 리소스에 대해 모든 레이블과 표현식을 비활성화
disabled: false
# kubernetes_labels는 Kubernetes 클러스터 레이블을 매칭합니다. 빈 값은 무시됩니다.
# kubernetes_labels_expression도 설정된 경우, 매칭 결과는 둘의 논리 AND입니다.
kubernetes_labels:
- name: env
values:
- dev
- staging
# kubernetes_labels_expression은 Kubernetes 클러스터를 매칭하는 레이블 조건 표현식입니다.
# 빈 값은 무시됩니다.
# kubernetes_labels도 설정된 경우, 매칭 결과는 둘의 논리 AND입니다.
kubernetes_labels_expression: 'labels["owner"] == "platform-team"'
default-kube health_check_config는 버전 [ kubernetes.health_check_min_version ]에서 도입되었으며, 모든 Kubernetes 클러스터가 헬스 체크에 참여할 수 있도록 합니다.
kind: health_check_config
metadata:
description: Enables all health checks by default
name: default-kube
spec:
match:
kubernetes_labels:
- name: '*'
values:
- '*'
version: v1
default-kube는 비활성화할 수 있지만 영구적으로 삭제할 수는 없습니다. tctl rm health_check_config/default-kube로 삭제하면 구성이 기본 설정으로 재설정되고 모든 Kubernetes 클러스터가 매칭되는 효과가 있습니다.
다른 default health_check_config도 존재하며, 헬스 체크를 위한 데이터베이스 매칭에 초점을 맞춥니다.
서로 다른 Kubernetes 클러스터 그룹에 대해 여러 개의 health_check_config 리소스를 생성할 수 있습니다. 동일한 Kubernetes 클러스터에 여러 health_check_config가 매칭되는 경우, 구성은 이름의 오름차순으로 정렬되며 첫 번째 구성만 적용됩니다(예: "00-my-config"라는 이름이 "10-my-config"보다 우선순위가 높습니다).
Kubernetes 헬스 체크 비활성화#
health_check_config에서 match.disabled 필드를 true로 설정합니다.
예를 들어 tctl edit health_check_config/default-kube를 사용합니다.
kind: health_check_config
metadata:
description: Enables all health checks by default
name: default-kube
spec:
match:
disabled: true
kubernetes_labels:
- name: '*'
values:
- '*'
version: v1
disabled: true인 경우 kubernetes_labels와 같이 정의된 레이블은 무시됩니다.
tctl 헬스 체크 명령어#
tctl get으로 기본 헬스 체크 구성을 읽습니다:
$ tctl get health_check_config/default-kube
tctl create로 새 헬스 체크 구성을 생성합니다:
$ tctl create health_check_config.yaml
tctl edit로 기존 구성을 대화형으로 업데이트합니다:
$ tctl edit health_check_config/default-kube
tctl rm으로 헬스 체크 구성을 삭제합니다:
$ tctl rm health_check_config/example
Teleport Kubernetes Service 인스턴스는 health_check_config의 변경 사항을 통보받고, Kubernetes 클러스터가 헬스 체크에 참여하는지 여부를 재평가하여 변경 사항을 적용합니다.
FAQ#
비정상 Kubernetes 클러스터 문제 해결을 위한 가이드가 있나요?#
헬스 체크에서 반환되는 특정 오류에 대해서는 Kubernetes Service 문제 해결 가이드를 참조하세요.
헬스 체크 메트릭으로 어떤 Kubernetes 클러스터가 비정상인지 확인할 수 있나요?#
아니요. 특정 Kubernetes 클러스터의 헬스는 teleport_resources_health_status_* 헬스 메트릭으로 확인할 수 없습니다.
메트릭에서는 비정상 Kubernetes 클러스터의 수량만 확인할 수 있습니다.
고가용성을 위해 헬스 체크를 구성하려면 어떻게 해야 하나요?#
추가 구성이 필요하지 않습니다.
여러 Teleport Kubernetes Service 인스턴스가 동일한 Kubernetes 클러스터로 프록시할 때 헬스 기반 연결 라우팅이 자동으로 이루어집니다.
동일한 Kubernetes 클러스터로 프록시하는 여러 Teleport Kubernetes Service 인스턴스로 고가용성을 구성해야 합니다.