

AWS 액티브/패시브 재해 복구 배포
Mattermost v11.8시작하기 전에 다음 사항이 준비되어 있는지 확인하십시오: 이 페이지는 AWS에서 Mattermost를 액티브/패시브 재해 복구 구성으로 설정하는 데 필요한 단계와 한 데이터 센터에서 다른 데이터 센터로 장애 조치하는 방법을 자세히 설명합니다.
시작하기 전에 다음 사항이 준비되어 있는지 확인하십시오:
- 두 리전 모두에서 RDS, S3, OpenSearch 리소스를 관리할 수 있는 IAM 권한이 있는 AWS 계정 접근 권한
- 장애 조치를 위한 기본 및 보조 AWS 리전 쌍 선택
- 정상적으로 운영 중인 기존 Mattermost 기본 배포
- 장애 조치 시 트래픽을 리디렉션할 수 있도록 Mattermost에 접근하는 도메인에 대한 DNS 제어 권한
- RDS Aurora PostgreSQL 글로벌 클러스터 권한 및 검증된 복원 가능한 데이터베이스 백업
- 두 리전 모두에서 세분화된 접근 제어(fine-grained access control)가 가능한 OpenSearch 2.x
- 기본 리전과 보조 리전 간의 네트워크 연결 확인 완료
이 페이지는 AWS에서 Mattermost를 액티브/패시브 재해 복구 구성으로 설정하는 데 필요한 단계와 한 데이터 센터에서 다른 데이터 센터로 장애 조치하는 방법을 자세히 설명합니다.
고가용성 및 액티브/액티브 지원을 위해 Kubernetes 배포를 안전하게 업그레이드하는 방법은 Kubernetes 및 고가용성 환경에서 Mattermost 업그레이드 문서를 참조하십시오.
단일 데이터 센터에 설정#
첫 번째 단계로, 단일 데이터 센터에 Mattermost를 설정합니다. 다음 다이어그램은 기본 단일 데이터 센터 아키텍처를 보여줍니다:
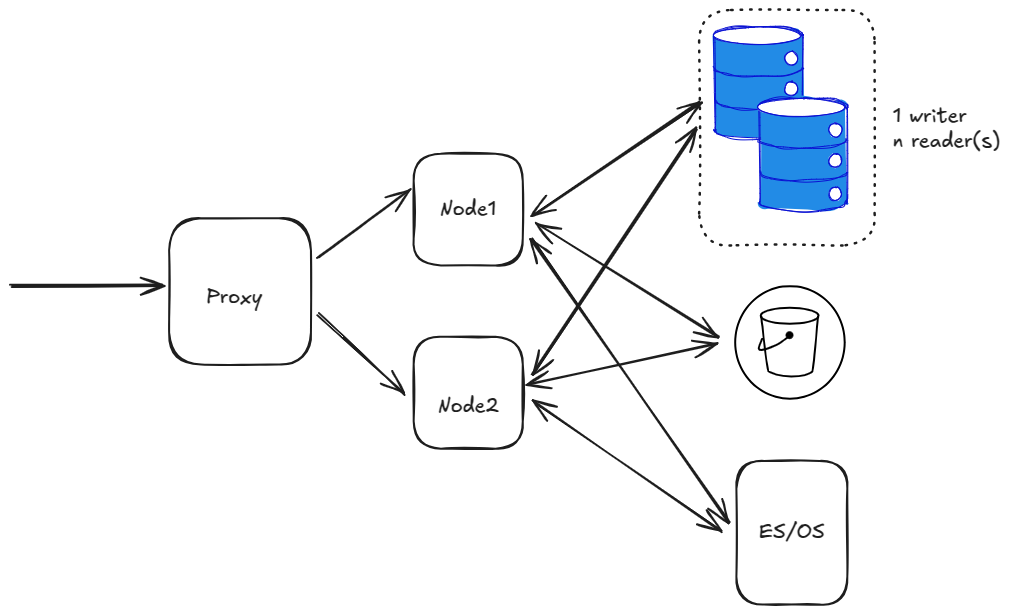
위 다이어그램은 단일 프록시가 2개의 노드에 트래픽을 전달하는 구성을 보여줍니다. 또한 단일 writer + n개의 reader를 가진 데이터베이스와 AWS OpenSearch 서비스를 사용하는 S3 버킷 및 ES/OS가 포함되어 있습니다.
이 단계에서는 LDAP/SAML, SMTP 등의 다른 세부 사항은 제외합니다.
다음 아키텍처는 전체 리전이 다운되는 경우에 구현됩니다. 단일 서버/서비스가 다운되는 경우는 다루지 않습니다. 예를 들어:
- 단일 앱 노드가 다운된 경우, 새 노드를 프로비저닝하는 모범 사례를 따르십시오.
- 데이터베이스 복제 노드가 다운된 경우, AWS 콘솔에서 새 복제본을 생성하거나, 자동으로 처리되도록 정책을 설정하십시오.
데이터베이스 복제#
다음 작업에서는 AWS 글로벌 클러스터를 생성합니다.
- AWS 콘솔에서 RDS 인스턴스를 선택하고 Actions 메뉴를 확장하여 Add AWS Region을 선택합니다.
- 보조 리전을 선택하고 나머지 세부 정보를 입력합니다.
보조 클러스터에서 Enable write forwarding 옵션을 선택하여 보조에서 기본으로의 쓰기 작업을 전달할 수 있도록 합니다. 자세한 내용은 AmazonRDS 쓰기 전달 문서를 참조하십시오.
또한 PostgreSQL 버전을 확인하고 write forwarding이 허용되는지 확인하십시오. 모든 PostgreSQL 버전에서 허용되는 것은 아닙니다. 자세한 내용은 Amazon RDS 쓰기 전달 리전 및 버전 가용성 문서를 참조하십시오.
이제 기본 클러스터가 us-west-1에, 보조 클러스터가 us-east-1에 있는 글로벌 클러스터가 생성됩니다:
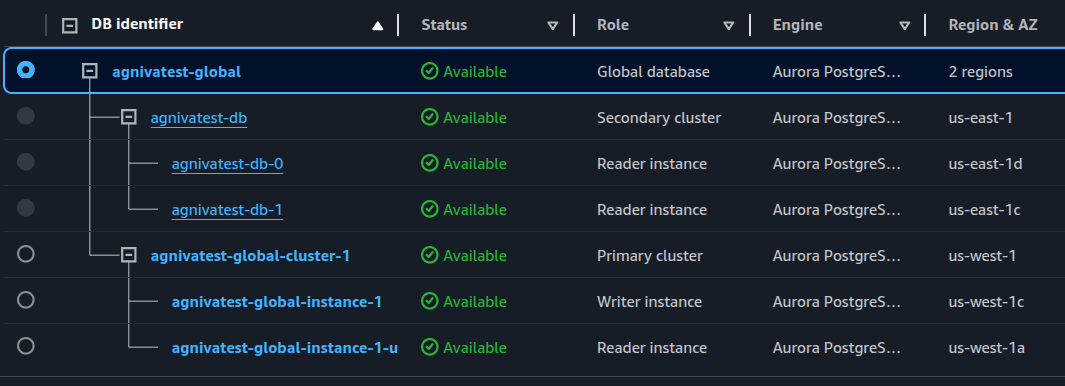
S3 버킷 복제#
- 보조 리전에 새 S3 버킷을 생성합니다.
- 원래 버킷으로 돌아가 Properties 탭으로 이동하여 Bucket versioning을 활성화합니다.
- Management 탭으로 이동하여 Replication Rules까지 스크롤을 내리고 새 복제 규칙을 생성합니다.
- 규칙에서 소스 버킷을 선택한 후 Apply to all objects in the bucket을 선택하여 버킷의 모든 항목을 복제합니다.
- 대상 버킷을 선택합니다.
- IAM 역할로 Create new role을 선택합니다.
- Save를 선택합니다.
- 기존 객체를 보조 버킷에 복제하는 작업을 시작할지 묻는 메시지가 나타나면 Yes를 선택합니다.
- 보조 버킷에도 동일한 단계를 수행합니다.
버킷의 Replica modification sync 옵션을 선택하여 복제 버킷과 소스 버킷이 서로 동기화된 상태를 유지하도록 합니다.
이제 S3 복제 버킷과 소스 버킷 간에 양방향 복제가 작동합니다.
ES/OS 스토리지 복제#
- ES/OS 스토리지를 복제하려면 다음 요구사항으로 AWS OpenSearch에 대한 CCR(cross-cluster replication)을 설정합니다:
- Elasticsearch 7.10 또는 OpenSearch 2.x
- 세분화된 접근 제어(fine-grained access control) 활성화
- 노드 간 암호화(node-to-node encryption) 활성화
- 또한 OS 도메인의 Security Configuration 탭 아래에 설정된 OS 클러스터의 IAM 정책에
CrossClusterGet권한을 추가해야 합니다. AWS 권장 사항에 따라 다음 설정을 권장하지만 필요에 따라 조정하십시오: - OpenSearch 2.x를 사용합니다.
- 세분화된 접근 제어를 활성화합니다.
- 마스터 사용자를 생성하고 서버 자격 증명을 기록합니다.
- 위와 같이 IAM 정책을 설정합니다.
- 보조 리전에 새 OS 클러스터를 생성합니다. 이 클러스터에도 동일한 단계를 반복합니다.
- 기본 리전에서 보조 리전으로 복제를 시작합니다.
- 이제 인덱스에 대한 복제 규칙을 설정합니다.
이미 OpenSearch 2.x를 실행 중인 경우 세분화된 접근 제어만 활성화하면 됩니다. 세분화된 접근 제어를 켜면 노드 간 암호화가 자동으로 활성화됩니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:ESHttp*",
"Resource": "arn:aws:es:<region>:<acc_num>:domain/<domain_name>/*"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:ESCrossClusterGet",
"Resource": "arn:aws:es:<region>:<acc_num>:domain/<domain_name>"
}
]
}요약:
마스터 사용자를 생성한 후, Mattermost 애플리케이션 노드에서 OS에 대한 IP 기반 접근이 작동하지 않을 수 있습니다. config.json의 ElasticsearchSettings 섹션에서 서버 사용자 이름과 비밀번호를 업데이트해야 할 수 있습니다.
이 단계에서 기본 리전의 모든 인덱스에 데이터가 채워져 있는지 확인하십시오. 아직 완료하지 않은 경우 대량 인덱싱(bulk index)을 실행하십시오.
a. 먼저 보조에서 기본으로의 연결을 생성합니다. OS의 복제는 "풀(pull)" 모델로 작동하므로 보조 사이트가 기본에서 데이터를 가져옵니다.
b. Amazon OpenSearch Service 콘솔에서 보조 도메인을 선택하고 Connections 탭으로 이동하여 Request를 선택합니다. c. Connection alias에 연결 이름을 입력합니다. d. connect to a domain in another AWS account or region을 선택하고 기본 도메인의 ARN을 입력합니다. e. Request를 선택하여 기본 도메인에 권한 요청을 전송합니다. f. 기본 도메인을 열어 Connections 탭에서 수신된 요청을 확인하고 수락합니다.a. 일별 명명 체계와 월별 집계로 인해 posts* 인덱스에 대한 자동 팔로우 규칙을 설정하려면 보조 리전의 앱 노드에 SSH로 접속합니다.
*를 사용하여 모든 것을 복제하는 규칙을 설정할 수도 있지만, 그러면 원하지 않는 숨겨진 인덱스와 시스템 인덱스도 포함됩니다.
c. posts* 인덱스에 대한 자동 팔로우를 설정합니다:
curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/_autofollow?pretty' -d '
{
"leader_alias" : "<LEADER_ALIAS>",
"name": "autofollow-rule",
"pattern": "posts*",
"use_roles":{
"leader_cluster_role": "all_access",
"follower_cluster_role": "all_access"
}
}'
d. 자동 팔로우 규칙의 상태를 확인합니다:
curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/autofollow_stats?pretty'
{
"num_success_start_replication" : 2,
"num_failed_start_replication" : 0,
"num_failed_leader_calls" : 0,
"failed_indices" : [ ],
"autofollow_stats" : [
{
"name" : "autofollow-rule",
"pattern" : "posts*",
"num_success_start_replication" : 2,
"num_failed_start_replication" : 0,
"num_failed_leader_calls" : 0,
"failed_indices" : [ ],
"last_execution_time" : 1737699113927
}
]
}
e. 이제 나머지 인덱스에 대한 복제를 설정합니다:
curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_start?pretty' -d '
{
"leader_alias": "<LEADER_ALIAS>",
"leader_index": "channels",
"use_roles":{
"leader_cluster_role": "all_access",
"follower_cluster_role": "all_access"
}
}'
curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_start?pretty' -d '
{
"leader_alias": "<LEADER_ALIAS>",
"leader_index": "users",
"use_roles":{
"leader_cluster_role": "all_access",
"follower_cluster_role": "all_access"
}
}'
curl -XPUT -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_start?pretty' -d '
{
"leader_alias": "<LEADER_ALIAS>",
"leader_index": "files",
"use_roles":{
"leader_cluster_role": "all_access",
"follower_cluster_role": "all_access"
}
}'
f. 복제 규칙의 상태를 확인합니다:curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_status?pretty'
curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_status?pretty'
curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_status?pretty'
curl -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/posts_<DATE>/_status?pretty'
Sample output:
{
"status" : "SYNCING",
"reason" : "User initiated",
"leader_alias" : "<LEADER_ALIAS>",
"leader_index" : "<INDEX>",
"follower_index" : "<INDEX>",
"syncing_details" : {
"leader_checkpoint" : 16,
"follower_checkpoint" : 16,
"seq_no" : 17
}
}
g. 인덱스를 확인합니다. 기본 도메인의 모든 인덱스가 보조 도메인에서도 확인 가능해야 합니다:curl -s -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_cat/indices?pretty'</code></pre>
<h2 id="잡-서버-복제">잡 서버 복제</h2>
<p>잡 스케줄러가 보조 리전에서 실행 중인 상태로 남아 있으면 잡을 가져와서 실행하기 시작합니다. 올바르게 관리하려면 다음 단계를 따르십시오. 자세한 내용은 <a href="/docs/mattermost/configure/environment-configuration-settings/#run-scheduler" class="doc-ref">RunScheduler 구성 설정</a> 문서를 참조하십시오.
- 사전 조건: 해당 리전을 활성화하기 전에 보조 리전의 모든 노드에서
JobSettings.RunScheduler를 false로 설정합니다.
- 장애 조치 시: 새 기본 리전의 모든 노드에서
JobSettings.RunScheduler를 true로 설정합니다.
- 직후: 새 보조 리전의 모든 노드에서
JobSettings.RunScheduler를 false로 설정합니다.
- 확인: 활성 리전에서만 잡이 실행되는지 확인합니다. 테스트 잡(예: 인덱스 재빌드 트리거)을 제출하고 잡 로그를 확인하여 보조가 아닌 새 기본에서 실행되는지 확인합니다.
보조 리전 테스트#
위 단계가 완료되면 완전히 기능하는 보조 리전이 준비됩니다. 기본 리전과 동일하게 노드와 프록시 서버를 설정할 수 있습니다. 보조 리전의 앱 노드는 처음에는 기동되지 않는데, Mattermost가 쓰기 전달과 함께 허용되지 않는 일부 DDL 구문을 실행하려 하기 때문입니다. 따라서 연결을 시도하는 루프에 빠질 것입니다. 리전 장애 조치가 완료되면 정상적으로 작동하기 시작합니다. 기본 리전은 여전히 읽기 가능하며, 주기적인 쓰기는 보조(현재의 기본)로 전달됩니다.
Warning동일한 데이터베이스를 2개의 클러스터에서 사용하려면 두 리전의 서로 다른 클러스터에 별도의 ClusterNames를 설정했는지 확인하십시오.
RDS를 보조로 장애 조치#
장애 조치를 수행하려면 RDS 글로벌 클러스터로 이동하고 Actions 아래에서 Switchover or Failover global database를 선택한 후 데이터 손실 없이 전환하려면 switchover를 선택합니다(완료까지 더 많은 시간이 소요됩니다). 또는 데이터 손실을 감수하고 빠른 장애 조치를 위해 failover를 선택할 수 있습니다. 전체 리전이 어차피 사용 불가능한 경우, failover는 switchover보다 더 나쁘지 않습니다.
이 작업이 완료되면 연결을 시도하다 멈춰 있던 앱 노드들이 정상적으로 진행되어 모든 것이 기능하게 됩니다. 읽기/쓰기, 이미지 업로드 등 모든 작업이 가능하며 복제됩니다. OpenSearch 데이터를 제외한 모든 것이 해당됩니다.
ES/OS를 보조로 장애 조치#
ES/OS는 단일 인덱스에 대한 멀티 writer를 허용하지 않습니다. 한 번에 1개의 인덱스에만 쓸 수 있습니다. 따라서 복제 방향을 반전하고 보조에서 기본으로 복제를 시작하려면 일부 수동 단계를 수행해야 합니다.
간단히 설명하면, site1이 기본이고 site2가 보조라고 가정합니다. 따라서 site1의 OS가 리더 도메인이고, site2의 OS가 팔로워입니다. 팔로워는 리더에서 데이터를 가져옵니다. site2가 리더가 되고 site1이 팔로워가 되도록 방향을 전환하려면:
- AWS 콘솔에서
site1 > site2 규칙을 삭제합니다. 복제가 자동으로 일시 중지되지만, site2의 인덱스는 여전히 읽기 전용입니다. 이에 대한 복제 규칙을 삭제합니다.
- 자동 팔로우 규칙을 삭제합니다:
curl -XDELETE -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/_autofollow?pretty' -d '
{
"leader_alias" : "<LEADER_ALIAS>",
"name": "autofollow-rule"
}'
- 앞서 설명한 대로 자동 팔로우 규칙의 상태를 확인합니다.
- 복제 규칙을 삭제합니다:
curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/channels/_stop?pretty' -d '{}'
curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/files/_stop?pretty' -d '{}'
curl -XPOST -H 'Content-Type: application/json' -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_plugins/_replication/users/_stop?pretty' -d '{}'
- 앞서 설명한 대로 복제 규칙의 상태를 확인합니다.
- 이제 인덱스가 쓰기 가능한 상태가 됩니다.
- AWS 콘솔에서
site2 > site1 규칙을 추가합니다.
site1에서 모든 인덱스를 팔로워로 설정합니다. 먼저 모든 인덱스를 삭제해야 합니다:curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/posts*?pretty'
curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/channels?pretty'
curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/files?pretty'
curl -XDELETE -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/users?pretty'
- 인덱스를 새로 고칩니다:
curl -XPOST -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_refresh?pretty'
- 모든 항목이 삭제되었는지 확인합니다:
curl -s -u '<USERNAME>:<PASSWORD>' 'https://<HOSTNAME>/_cat/indices?pretty'
- 자동 팔로우 규칙을 추가하고 복제 규칙을 설정합니다. 이전과 동일한 단계를 따르십시오.
- 인덱스를 다시 나열하여 복제가 시작되었고 인덱스가 사용 가능한지 확인합니다.
NoteS3 버킷이 양방향으로 자동 복제되도록 하기 위해 별도로 수행해야 할 작업은 없습니다.
엔드 투 엔드 테스트#
장애 조치가 완료되고 ES/OS 복제 방향이 전환되면, 새 사이트를 정상적으로 사용할 수 있습니다.
최종 아키텍처는 다음과 같습니다:
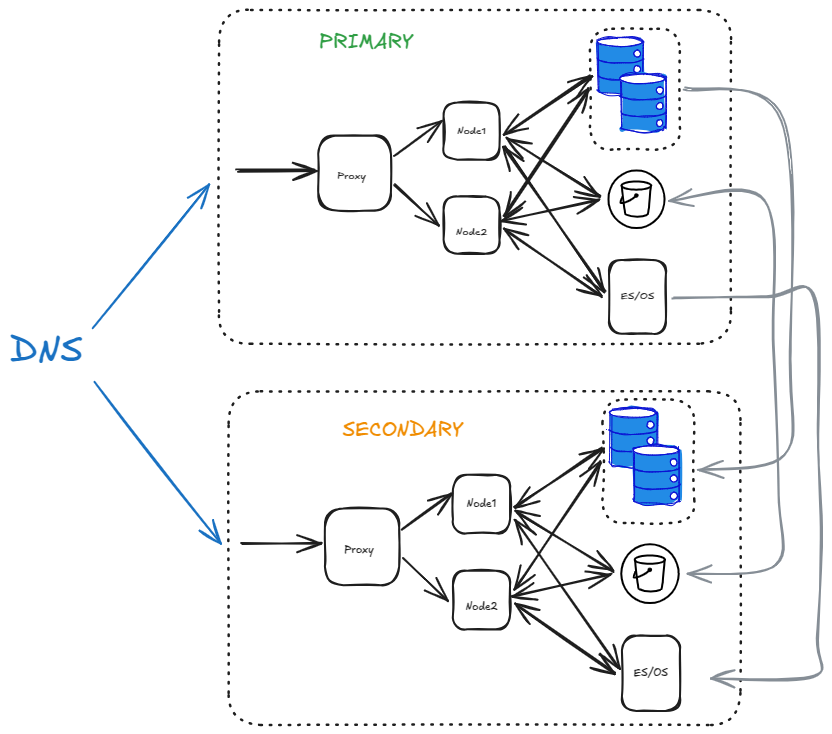
장애 조치 시 DNS를 사용하여 PRIMARY와 SECONDARY 간에 쉽게 전환할 수 있습니다.
TipDNS를 전환한 후에도 웹소켓은 여전히 이전 데이터 센터를 가리킵니다. 해당 연결을 새 데이터 센터로 이동하려면 각 앱 노드를 단계적으로 롤오버해야 합니다. 모든 노드가 다운된 경우에는 별도의 조치가 필요하지 않으며, 클라이언트가 자동으로 새 데이터 센터에 재연결합니다.
S3 버킷은 양방향으로 복제되는 반면 데이터베이스와 ES/OS는 단방향으로 복제됩니다.
기본 데이터 센터로 복원#
재해 이벤트가 해결되어 정상 운영을 복원할 준비가 되면, 동일한 장애 조치 단계를 반대로 수행하여 트래픽을 원래 기본 데이터 센터로 되돌립니다:
- RDS 콘솔의 Switchover or Failover global database 옵션을 사용하여 RDS를 원래 기본 리전으로 다시 전환합니다.
ES/OS를 보조로 장애 조치 섹션의 동일한 단계에 따라 site1과 site2의 역할을 바꿔 ES/OS 복제 방향을 역전합니다.- 원래 기본 데이터 센터로 트래픽을 다시 리디렉션하도록 DNS를 업데이트합니다.
- 원래 기본 노드에서
JobSettings.RunScheduler를 다시 활성화하고 보조 노드에서는 비활성화합니다.
- 웹소켓 연결을 기본 데이터 센터로 되돌리기 위해 앱 노드를 단계적으로 롤오버합니다.