

Mattermost 성능 알림 가이드
Mattermost v11.8Mattermost는 Prometheus 와 Grafana 를 사용하여 Mattermost 애플리케이션 서버의 성능 지표를 추적하는 것을 권장합니다. 성능 부하 분산을 위해 서버가 추가된 5,000명 이상의 사용자 배포에서는 성능 알림을 설정하는 것을 강력히 권장합니다.
Mattermost는 Prometheus 와 Grafana 를 사용하여 Mattermost 애플리케이션 서버의 성능 지표를 추적하는 것을 권장합니다. 이 가이드의 목적은 시스템 상태 추적을 설정 한 후 Grafana 대시보드에 알림을 설정하는 데 도움을 드리는 것입니다.
성능 부하 분산을 위해 서버가 추가된 5,000명 이상의 사용자 배포에서는 성능 알림을 설정하는 것을 강력히 권장합니다.
전제조건#
Mattermost의 성능 모니터링을 설정하세요. 자세한 내용은 성능 모니터링 문서를 참조하세요.
알림을 받으려면 먼저 Grafana에서 알림 채널을 설정하세요. Mattermost에서 자동으로 알림을 게시하도록 설정하는 방법은 다음과 같습니다:
- Mattermost에서:
- Grafana에서:
a. 알림 채널을 생성하세요.
b. 알림 채널에 대한 수신 웹훅 을 생성하고 URL을 복사하세요.a. 사이드바의 알림 아이콘 아래에서 연락처 를 선택하세요.
b. 연락처 생성 을 선택하세요. c. 이름으로 Mattermost Alerts Channel 을 입력하세요. d. 유형으로 Slack 을 선택하세요. e. URL 필드에 웹훅 URL을 붙여넣으세요. f. Mattermost에 알림이 게시될 때 멘션을 보내려면 멘션 필드에 @ 멘션을 포함하세요. g. 테스트 전송 을 눌러 알림을 테스트하세요.이메일 알림도 받으려면 이 지침 을 따라 설정할 수 있습니다.
알림 구성#
Grafana용 Mattermost 대시보드 에는 다음 차트에 부분적으로 미리 구성된 알림이 있습니다:
* CPU 사용률
* 메모리 사용량
* Goroutine 수
* 초당 API 오류 수
* 평균 API 요청 시간
알림을 구성하려면 적절한 임계값을 설정하고 알림을 활성화하세요. 알림 활성화는 각 차트에 동일하지만, 올바른 임계값 설정은 차트별로 다르게 처리하는 것이 좋습니다.
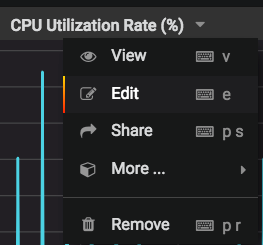
- 각 차트에서 차트 이름을 선택한 다음 편집 을 선택하세요:
- 알림 탭을 선택하세요:
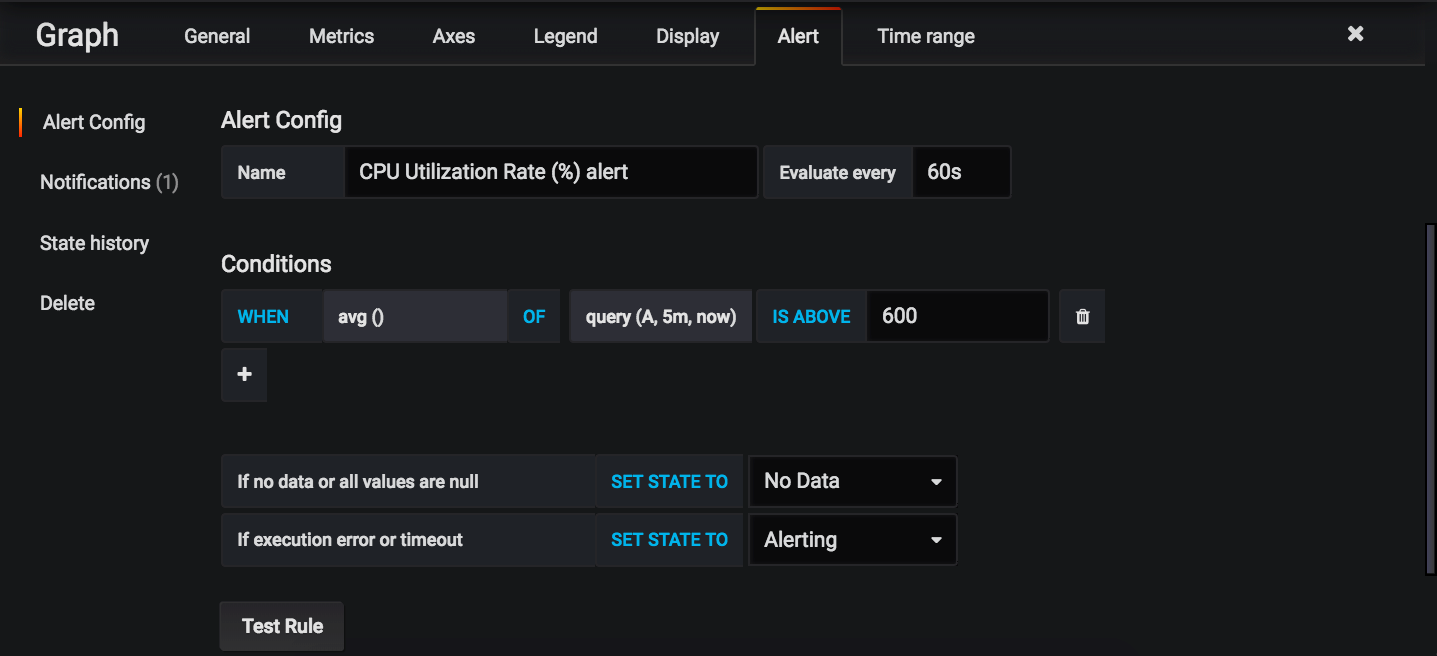
- 아래 섹션에서 설명할 알림 임계값은 조건 아래의 마지막 필드입니다(위 스크린샷에서 600으로 설정된 것).
- 모든 알림에 대한 알림을 활성화하려면 왼쪽의 알림 탭을 선택한 다음 보내기 아래에서 Mattermost Alerts Channel 을 선택하세요:
각 차트에 대한 임계값 설정 방법은 아래 섹션을 참조하세요. 자신만의 사용자 정의 알림 조건을 추가하려면 여기에서 구성하세요.

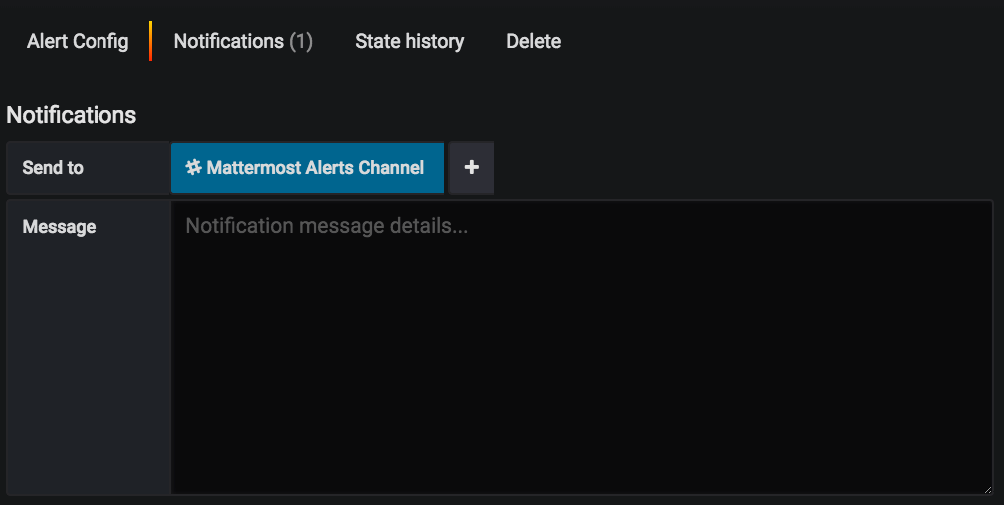
알림에 더 많은 컨텍스트를 추가하려면 메시지를 입력하세요.
기본적으로 알림은 마지막 1분 동안의 차트 평균을 확인하여 해당 값이 임계값을 초과하는지 확인하도록 구성되어 있습니다. 임계값을 초과하면 알림이 트리거됩니다. 마지막 1분 동안의 평균이므로 임계값을 초과하는 작은 스파이크가 반드시 알림을 유발하지는 않습니다. 이는 사용량의 자연스러운 스파이크로 인한 위양성을 방지하는 데 도움이 됩니다. 각 차트의 알림 상태는 1분마다 평가됩니다.
사용 가능한 차트#
아래 섹션에서 각 차트를 더 자세히 설명합니다.
CPU 사용률#
CPU 사용률은 상당히 간단합니다. CPU 사용률은 앱 서버의 CPU 사용량을 백분율로 추적합니다. 최대 백분율은 앱 서버에 있는 CPU 코어 또는 vCPU의 수를 기반으로 합니다. 예를 들어, CPU 코어가 4개이고 모든 4개 코어에서 앱 서버가 100% 사용률이면 해당 앱 서버에 대해 그래프는 400%를 표시합니다.
알림 임계값은 평균 CPU 사용률과 앱 서버의 코어/vCPU 수를 기반으로 설정하는 것이 가장 좋습니다. 지난 7일 동안의 차트를 확인하세요. 최대 CPU 사용량(코어 × 100)과 관찰되는 CPU 사용량 사이 어딘가에 임계값을 설정하세요. 임계값을 낮게 설정할수록 더 많은 알림, 즉 더 많은 위양성이 발생합니다. 임계값을 너무 높게 설정하면 인시던트가 악화될 때까지 알림을 받지 못할 수 있습니다. 이 원칙은 차트에 관계없이 모든 알림에 동일하게 적용됩니다.
예를 들어, 커뮤니티 서버에서는 임계값을 15%로 설정했습니다:
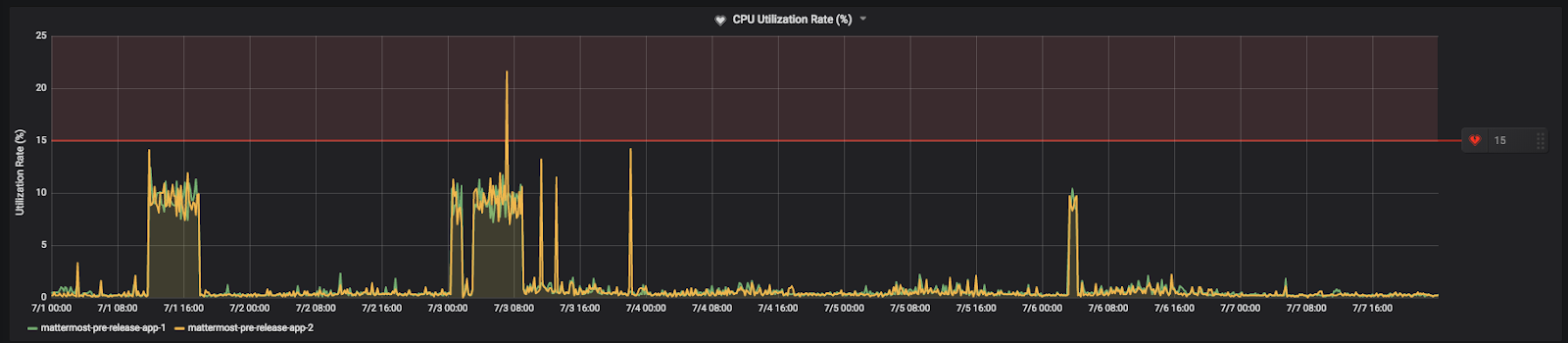
이 값은 최대 CPU 사용량 이하이고 피크 시간 평균 사용량 이상입니다. 따라서 비정상적으로 높은 CPU 사용량이 발생하기 시작하면 알림을 받게 됩니다.
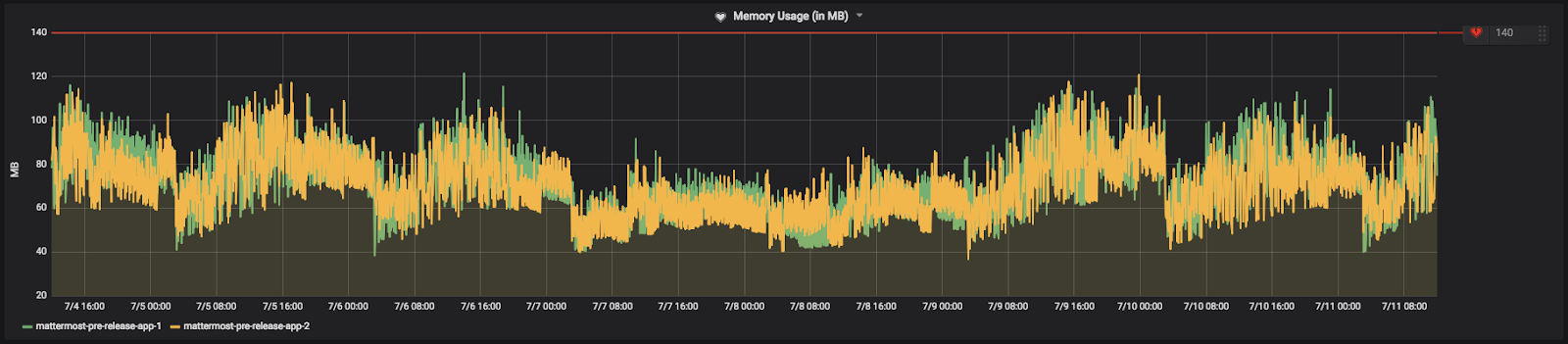
메모리 사용량#
메모리 사용량은 앱 서버가 사용하는 RAM의 메가바이트를 추적합니다. CPU 사용률과 유사하게 임계값을 설정하세요: 사용 가능한 최대 메모리 이하, 피크 시간 평균 사용량 이상.
커뮤니티 서버에서 알림이 설정된 방식은 다음과 같습니다:
Goroutine 수#
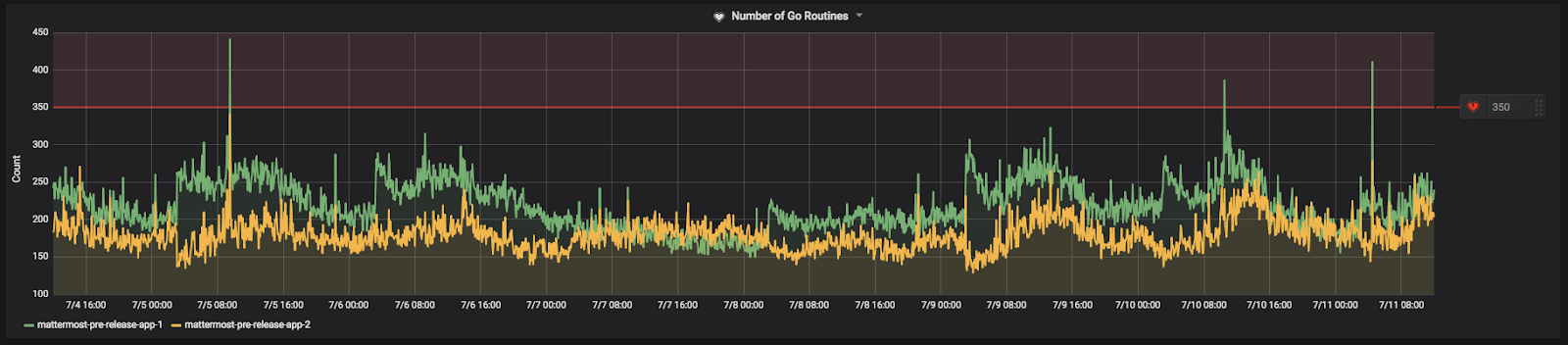
Goroutine은 다른 함수 및 메서드와 동시에 실행되는 함수 또는 메서드입니다. Goroutine은 낮은 생성 비용을 가진 경량 스레드와 같습니다. 증가하는 Goroutine 수는 앱 서버의 성능을 측정하는 좋은 지표가 될 수 있습니다. 지속적인 증가는 앱 서버가 처리를 따라가지 못하고 Goroutine이 작업을 완료하고 종료하는 것보다 더 빠르게 Goroutine을 생성하고 있음을 나타냅니다.
피크 부하 시간 동안 관찰되는 평균 Goroutine 수보다 약간 높은 곳에 임계값을 설정하세요. 작은 스파이크는 일반적으로 걱정할 필요가 없습니다. 주의해야 할 것은 Goroutine의 통제되지 않는 증가입니다.
커뮤니티 서버에서 설정된 방식은 다음과 같습니다:
초당 API 오류 수#
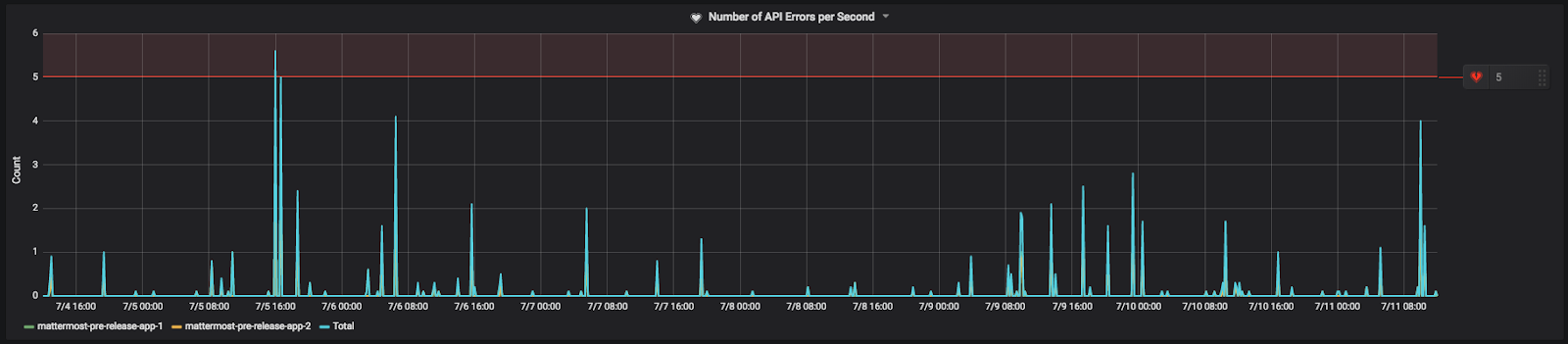
4xx 또는 5xx HTTP 응답 상태 코드는 REST API 오류로 계산됩니다. API 오류 자체가 반드시 문제인 것은 아닙니다. API 오류가 발생하는 많은 정당한 이유가 있습니다. 예를 들어 사용자의 세션 만료나 클라이언트가 리소스 존재 여부를 확인하여 404 Not Found 응답을 받는 경우입니다. 설치 기반에 따라 일부 API 오류가 발생하는 것은 정상입니다.
그렇지만 REST API에 대한 오류는 배포 및 기타 문제를 나타낼 수 있습니다. 예를 들어, 어떤 이유로 앱 서버 중 하나가 올바르게 배포되지 않은 경우 많은 수의 API 오류를 반환하기 시작할 수 있습니다. 또 다른 예로는 잘못된 요청으로 API를 스팸하는 오작동 봇이 있습니다. API 초당 오류에 대한 알림은 이러한 문제 및 기타 문제를 발견하는 데 도움이 됩니다.
커뮤니티 서버에서 설정된 방식은 다음과 같습니다:
평균 API 요청 시간#
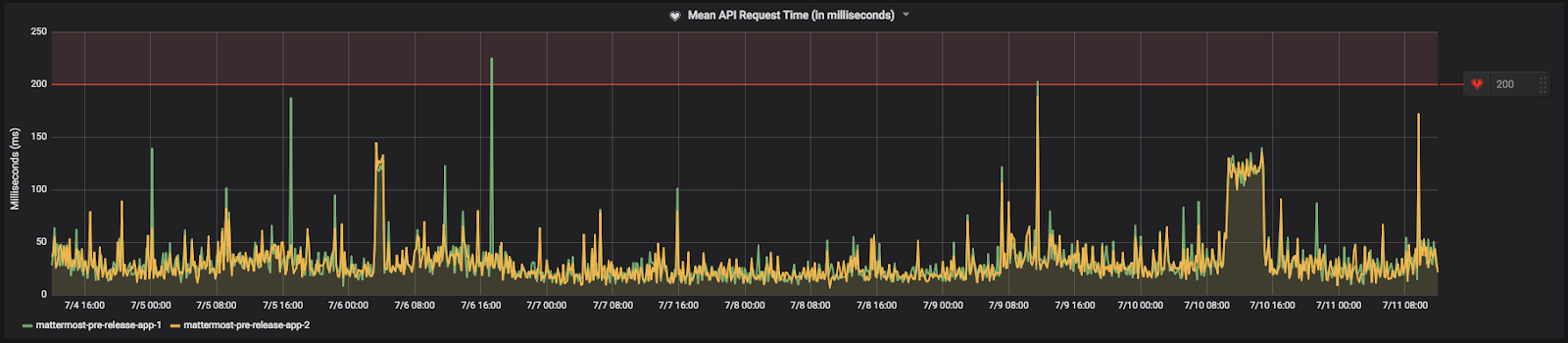
평균 API 요청 시간은 Mattermost 앱 서버에 대한 REST API 요청이 완료되는 데 걸리는 평균 시간입니다. 앱 서버의 성능이 저하되기 시작하면 요청을 완료하는 데 더 오랜 시간이 걸리기 때문에 평균 요청 시간이 증가하는 것을 볼 수 있습니다. 이는 데이터베이스가 앱 서버의 부하를 감당하지 못하는 경우에도 발생할 수 있습니다. 또한 앱 서버와 프록시 간의 문제를 나타낼 수도 있습니다.
피크 부하 시간 동안의 평균 요청 시간보다 약간 높은 곳에 알림 임계값을 설정하세요.
커뮤니티 서버에서 설정된 방식은 다음과 같습니다:
플러그인 훅#
Prometheus를 사용하여 훅 및 플러그인 API 호출을 추적할 수 있습니다. 다음은 서버 성능을 문제 해결하거나 모니터링할 때 알아두어야 할 훅 및 API Prometheus 지표의 예시입니다.
# HELP mattermost_plugin_hook_time Time to execute plugin hook handler in seconds.
# TYPE mattermost_plugin_hook_time histogram
mattermost_plugin_hook_time_bucket{hook_name="ChannelHasBeenCreated",plugin_id="com.mattermost.demo-plugin",success="true",le="0.005"} 0
mattermost_plugin_hook_time_bucket{hook_name="ChannelHasBeenCreated",plugin_id="com.mattermost.demo-plugin",success="true",le="0.01"} 0# HELP mattermost_plugin_multi_hook_time Time to execute multiple plugin hook handler in seconds.
# TYPE mattermost_plugin_multi_hook_time histogram
mattermost_plugin_multi_hook_time_bucket{plugin_id="com.mattermost.custom-attributes",le="0.005"} 100
mattermost_plugin_multi_hook_time_bucket{plugin_id="com.mattermost.custom-attributes",le="0.01"} 100# HELP mattermost_plugin_multi_hook_server_time Time for the server to execute multiple plugin hook handlers in seconds.
# TYPE mattermost_plugin_multi_hook_server_time histogram
mattermost_plugin_multi_hook_server_time_bucket{le="0.005"} 1043
# HELP mattermost_plugin_api_time Time to execute plugin API handlers in seconds.
# TYPE mattermost_plugin_api_time histogram
mattermost_plugin_api_time_bucket{api_name="AddUserToChannel",plugin_id="com.mattermost.plugin-incident-response",success="true",le="0.005"} 0
mattermost_plugin_api_time_bucket{api_name="AddUserToChannel",plugin_id="com.mattermost.plugin-incident-response",success="true",le="0.01"} 0</code></pre>
<h2 id="기타-알림">기타 알림</h2>
<p>더 많은 알림을 원한다면 원하는 Grafana 차트에서 설정할 수 있습니다. <a href="/docs/mattermost/scale/performance-monitoring/" class="doc-ref">성능 모니터링 기능 문서</a> 에 나열된 사용자 정의 지표를 검토하는 것을 권장합니다.